原始社会
刚来创业公司的时候,被这简单粗暴的“架构”设计震惊了,准确的说,这里并没有什么设计。整个后端就一个单体程序,整体结构和大学里写的三层架构差不多,好吧,好歹还做了一些分层。设计模式就别想找到了,面向对象都很少见。
作为初创员工加入后,发现其实这种代码在人少时还挺高效的。本地搞点配置写个脚本,几秒内就可以把新代码发布到线上。
此时我们大致的架构是这样的:
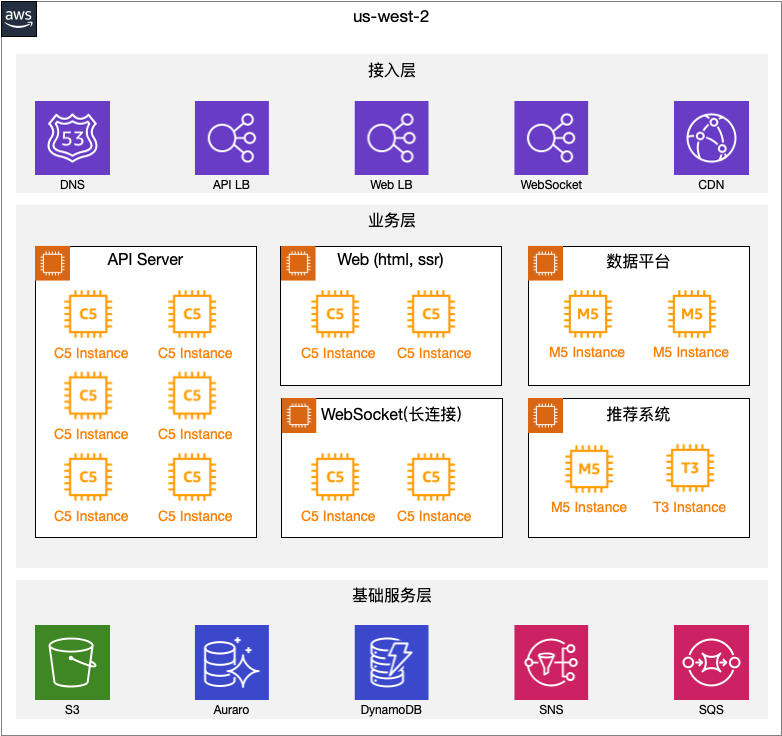
但随着团队的扩张,2人、5人、10人,当 10 个人往同一个没有良好设计的项目里 commit 代码的时候,问题也慢慢地开始显现了。
代码冲突,发布依赖,线上雪崩… 是时候开始微服务化了。
2018年7月,我们的转型之路正式开始。
本文主要是介绍了我们做 Service Mesh 的技术背景和实施路线和每个阶段遇到的问题。其中有一些问题值得拿出来单独讲讲,所以后面还会有一篇篇的详解。
文中类似这样的标注:
(1),可以去文章最后找到对应文章,看到更多内容。
大众点评的微服务实践与经验
在我们开始的时候,正是 Service Mesh 开始流行的时候,对我们来说这是一个全新的概念,但是这和以前的微服务有什么区别呢?
为了搞清楚这些问题,当然要参考一下老东家走过的那些路:高可用性系统在大众点评的实践与经验
文中有几个关键的阶段:
- 幼儿时期:2012年前,使命:满足业务要求,快速上线。
- 少年时期:垂直拆分(2012-2013),使命:研发效率 & 故障隔离。
- 青年时期:服务做小,不共享数据(2014-2015),使命:支撑业务快速发展,提供高效、高可用的技术能力。
- 成年时期:水平拆分(2015至今),使命:系统要能支撑大规模的促销活动,订单系统能支撑每秒几万的 QPS,每日上千万的订单量。
同时,我也联系了一些点评正在做服务治理的同事,了解到他们虽然在调研 Service Mesh,但是并没有启动 Service Mesh 相关的改造。美团的 OCTO 路线图中有准备在 2.0 中把 Agent 模式改造成 Proxy 模式,和 Service Mesh 里的 Sidecar 其实已经很接近了。但现在依然还是 Agent 模式,流量不经过 Agent。
为什么他们不做 Service Mesh 转型?
我们应该先做微服务改造然后再做 Service Mesh 还是直接上 Service Mesh?
举步维艰的微服务化
一开始因为更熟悉 Java 和大众点评那套架构设计,那自然就会优先选择 Java 生态链下的各种产品,包括大众点评,蚂蚁金服,携程还有 Spring Cloud 全家桶等。
但在我构思从哪开始,一步步怎么走的时候,我快哭了。虽然 Java 生态链下开源产品很多,但不是一整套的解决方案。跨语言,RPC,服务注册与发现,监控,日志,分布式追踪,熔断,重试… 每一个问题拿出来都要做很久,不仅中间件开发成本大,所有的中间件也都要侵入代码,开发人员的成本也非常大。
一颗银弹
正当我苦恼时,看到 Istio 1.0 发布了,Service Mesh 这个概念再一次出现在我们的面前。Istio 中的 Sidecar 模式也一下子把我们吸引过去了。
Service Mesh 的详细介绍可以看这篇文章:Service Mesh:下一代微服务
看起来它好像解决了我们大部分的问题:跨语言,监控,分布式追踪,熔断,重试…
我们也突然明白为什么大公司很难做 Service Mesh 转型了,因为他们已经有了很多成熟的中间件来解决这些问题。在没有大问题前推倒重来是不现实的。国内走得最快的应该是蚂蚁金服了,基于 Istio 改造扩展了 SOFAMesh。
另一个问题也慢慢变得清晰了,我们还需要先做微服务再做 Service Mesh 吗?很明显答案是否定的。
Service Mesh 不是一个慢慢演进的产物,而是一个颠覆的产物。对于我们这种处于原始社会的架构设计来说,直接开始比慢慢演进更容易。
技术选型
整个技术选型的过程没有很曲折,因为可选的方案不多。
想要上 Service Mesh 那容器编排基本是逃不掉的,而 Kubernetes 基本就是容器编排的唯一标准了。
而 Istio 也没有太多竞争对手,当时没有,到现在基本也没有。
AWS 后来出了一个 App Mesh, Sidecar 也是和 Istio 一样用的 Envoy,所以本质上并没有太大的区别。最大的优势就是控制平面可以不需要自己维护的,AWS 帮你托管了,这个算是一个最大的优势了。
其实,就算未来 Kubernetes 和 Istio 出现了继承者,Service Mesh 下开发的业务也是低侵入,容器化的。后续再迁移到别的技术栈并不是一个太复杂的过程。再加上 Kubernetes 和 Istio 背靠 Google,也给了我们更多的信心。
集群搭建
在 Kubernetes 集群的搭建上,也没有太多选择。一个是官方出的 kubeadm,便于你搭建集群和后续的集群维护。而另一个是官方出的 kops,两者最大的区别是 kubeadm 主要是针对裸机操作的,而 kops 是对云厂商操作的。
举个例如,如果你要搭建一个集群,用 kubeadm 的话集群你总要自己准备好吧。而 kops 不用,你选择好你的云厂商,并配置好对应的权限后,它可以做到一条龙服务,包括建机器,建集群,磁盘,负载均衡等都可以帮你一条龙搞定。
你要做的只是维护一份 yaml 文件来管理你的集群配置而已。我们的服务在 AWS 上,kops 会帮你装上所有 AWS 相关的插件,例如 Amazon EBS 存储插件,你在集群内直接创建PersistentVolumeClaim后插件就会自动帮你在 Amazon EBS 里创建一块磁盘了。
kops 虽然是一条龙服务,但是它的使用方式非常可控。不像别的一些傻瓜式的软件,它做了什么你都不知道。
这里的可控主要体现在无论你是创建还是修改集群,修改完 yaml 配置提交变更前,它都会像git diff一样告诉你哪些资源被改了,哪些资源被删了。
除此以外,所有建出来的资源,例如 EC2,你都可以直接登陆上去,这个在排查问题的时候帮助也是很大的。
Istio 的配置
Istio 跑起来不难,配置好不容易。
首先是 Istio 1.0 刚发布,业内根本没有参考。所以通读 Istio 文档是必须的。还好 Istio 文档整体写的非常不错,也有丰富的例子。自己根据它的例子上手做一遍,大致怎么玩就知道了。
但是初期版本的 Istio 文档还是略显简陋,很多细节并没有在文档中体现。
例如用作流量控制的DestinationRule里的很多参数就找不到细节。Istio 本质上是下发配置给 Envoy,所以这块最后是根据 Envoy 的配置再去翻查 Envoy 的文档来理解的。
还有比如 Istio 中怎么把特定的一个Deployment禁用 Sidecar 呢?最早的文档中也是没有的,但是在底层却发现了相关的参数,最终翻查 Istio 源码的过程中终于找到了相关配置。
随着 Istio 新版本的发布,这些初期遇到的问题其实他们都可以很好的解决了。现在开始用的人并不一定会遇到这些问题。
可行性验证
到了这步,各种 Demo 都跑得差不多了,但不去真刀实枪的干一下,很多问题是不会暴露出来的。不去实战验证一下的话,也是不敢大规模推广的。
这里我主要想解决这些问题:
哪些业务更适合用来做实验?
一种拆法是垂直拆分,如果原来的单体程序中业务都比较独立,那这样是可行的。但事实并不是这样,虽然我们各个业务都是独立的,但是中间公用的业务还不少。例如一个block功能,用户可以把别人block,而block之后在上层很多代码中需要做检查。
所以,水平拆分看起来是一个更可行的方案,而且也只能从底层开始,把依赖最少的模块独立出来。例如上面提到的block功能,它内部只依赖了数据库,并不会再涉及到别的业务了。
这个功能的调用量不小,功能简单,就算完全挂了也不会有严重的影响,看似是一个非常适合的小白鼠。于是我们第一个 Service Mesh 项目block-sercice就诞生了。
如果第一个项目验证通过后,未来怎么继续迁移呢?我觉得可以继续按照这个思路去做迁移。把整个项目内部模块想像成一个树的话,从叶子节点慢慢的开始迁移,最终把整棵树挪过去。
新老架构如何互通?
这个问题不难解决,老的单体程序虽然在 Kubernetes 集群外,但是完全可以通过 HTTP 访问。虽然这不是性能最佳的方案,但如果只是迁移过程中的方案的话,并不是不可接受。因为这个阶段小步快跑,灵活掉头更重要。
独立成服务后会出现哪些问题?
这个问题在开发和上线运行的过程中出现了很多,最大的问题是很多标准和基础设施的缺失。虽说 Service Mesh 是一颗银弹,但这颗银弹不能解决所有微服务化下需要解决的问题,还是有很多东西需要亲自操刀的。
独立成服务后性能有多大的差别?
不用测就知道这块肯定是有非常大的性能差异的。代码直接调用改成 RPC,那单纯的性能必定是成倍的下降。这是不可避免的,要解决它,我觉得依然从单纯性能角度去解决是没有出路的,网络请求的瓶颈摆在那,这是无法逾越的。
要解决它,只盯着一个请求看不行的,应该从更高的角度看整个调用链,然后想办法去做优化。
后面也会有专门的文章介绍我在这块的思考。(9)
Kubernetes 和 Istio 的组合是否稳定?
这个问题在第一个项目验证的时候,并没有体现,但在后续越来越多项目迁入的时候,都发现了一些问题。(1) (2)
验证的过程中如何做故障转移、一键或自动切换到老代码?
这个问题也不难,我在我们老的单体程序里面实现了一套限流,熔断,故障转移的机制。如果 Kubernetes 集群内的服务挂了,直接访问老代码,这样就完全不会影响线上业务了。
最后,这个项目上线后,后面要做什么我们也越来越清晰了。在验证它可靠性的同时,我们也开始一步步解决上面遇到的问题了。
目前和以前最大的区别就是,以前 block 相关的业务是直接访问数据库的,现在是先访问 Kubernetes 集群内的 block-service,由这个服务访问相关数据库。
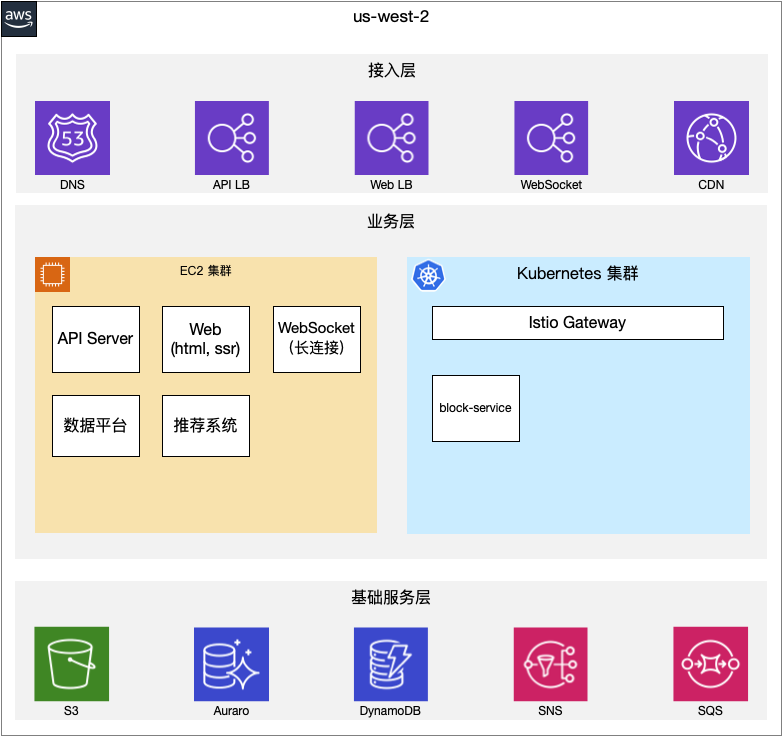
基础设施基本可用
之前提到各种标准和基础设施的缺失阻碍了我们前进的步伐,不把这个解决大家就没办法继续了。总不能让大家自己手工 build 镜像,自己上传,再自己手写 yaml 吧。
先不管好不好用,第一个短期目标起码是可用,从整个项目的开发运作来看,主要需要这些东西:
RPC 协议
对于 Service Mesh 架构来说,服务发现,注册中心,健康检查这些问题在 Kubernetes 中根本就不是问题了,因为它本身已经提供了很好的支持;然后 Istio 又帮你解决了流量控制这块的需求。
但是最终协议还是需要自己选择一下的,是直接用 HTTP 还是 gRPC?Istio 目前也只支持这两种协议。从性能角度来看,gRPC 肯定是更好的选择,gRPC 基于 HTTP/2,所以拥有 HTTP/2 的各种特性,再加上 gRPC 在编码解码上的特性,速度比 HTTP 要快非常多。
因为 gRPC 基于 HTTP/2,其实两者并不冲突,很多 gRPC 的概念都是和 HTTP 一一对应的。例如 gRPC 里的 Metadata 本质上就是 HTTP Header。同一个微服务完全可以同时提供两种协议,而且业务代码完全是一样的。只要在外层做一层适配器,写一下路由,用一些工具类把 gRPC Metadata 和 HTTP Header 提取一下变成一个map,后面业务只管处理业务就行了,并不需要做额外的工作。
另外这个项目 grpc-gateway,可以直接把 gRPC 封装成一个 HTTP 服务,额外多一次网络请求,具体怎么实现根据你的场景来选择。
虽然 gRPC 在语言的支持上已经非常丰富了,但我们一开始还要支持老的单体程序,老项目是 Python,用 gRPC 还是遇到了不少问题的。所以早期阶段我们的服务先只提供 HTTP 的接口,后续的业务慢慢加上了 HTTP 和 gRPC 双协议支持。长期的发展应该是 gRPC 为主,按需提供 HTTP 接口。
项目打包标准
Kubernetes 做容器编排,那么容器化是必须的了。但是镜像并不能直接在 Kubernetes 中欢快地跑起来,除了镜像,你还缺了很多 Kubernetes 资源配置。
理论上,Kubernetes 资源配置大部分内容是相似的,对于一个微服务来说总是需要这些东西:Pod,Service,HorizontalPodAutoscaler等,但因为我们公司技术栈比较分散,暂时还很难做一些通用的模版。所以前期我们会把 Kubernetes 资源配置以 Helm Chart 的形式放在代码仓库中,CI / CD 不仅仅会 build 镜像,还会打包 Helm Chart。
而后面同质化的项目越来越多后,我觉得可以提供一种零配置的选择,让简单的业务可以不用自己去维护 Helm Chart 了。
CI / CD
我们调研了不少理念和工具。在前期通过 Jenkins Pipeline 实现了一个可用版,但还缺失了很多功能,只能说基本可用。(7)
监控,报警
Prometheus 是 Cloud Native 的顶级项目,对 Kubernetes 的支持当然不在话下。Prometheus + Grafana 也是这里最佳的选择。
分布式追踪
Istio 的蓝图中,可观测性是一个很大的亮点。所以前期我们分布式追踪也用了 Istio 内置 Jeager 的解决方案。(2)
日志搜集
依然是 Cloud Native 中的开源项目,Fluent Bit 是针对 Kubernetes 用 C 语言重现的 Fluentd。它针对 Kubernetes 做了很多优化。
再配合 Elasticsearch,可以基本满足我们对日志搜集的需求。
完善文档
整个 Service Mesh 推进的过程中,大量的新概念出现,特别是前期很多基础设施不完善的时候,开发更需要去学习更多技术细节。在整个基础设施从零到可用的过程中,我们也把所有的东西怎么搭建,怎么配置,怎么使用全部写成了内部文档。为团队成员提供了便利,也节约了自己的时间。
这个阶段经历了几个月的时间,同时,最早迁移的block-service也稳定运行半年左右了,准备就绪!
新项目越来越多,老项目越迁越多
验证完可行性,基础设施基本可用后,整个转型进度走上了快车道。
2019 年年初,正好有个大项目需要开发很多新的独立的模块;同时,有很多老项目用 MySQL 已经无法支撑,需要重写并采用别的数据库方案。这两个场景正好和技术转型非常对口。
在2019年年底的时候,我看了看 Jenkins 上的项目,竟然已经到了 100+,线上集群 Pod 数量也达到了 1000+。
基础设施改进
在 2019 年 Service Mesh 快速推进的时候,所有人对各种基础设施的要求也不再仅仅满足于可用了,一个个需求冒了出来。
但实战中的需求会比脑补出来的需求靠谱很多,很多时候不怕没需求,就怕需求没想明白。
整个 2019 年至今,我们发现并解决了这些问题:
Kubernetes Master 节点性能问题
在使用kops的过程中我们出现过2个大问题,每次都造成了分钟级别的线上宕机,最后我们迁移到了 Amazon EKS。(1)
Istio 性能问题
Istio 的 Mixer 模块对性能的影响不小,而且整体来说 Mixer 并不好用。(2)
数据库中间件
为什么数据库需要中间件而不是直接访问呢?有人可能会想到会不会是因为微服务化后服务太多,连接数太多?这的确是一个问题,但在良好的设计下,一个业务应该是一套独立的数据库,不应该出现那种被大量业务直接访问的数据库。如果有,那么这样的数据库应该被做成一个微服务。
我们做这个主要是想解决多语言读写分离的需求,因为我们内部语言多,很难为所有语言找到好用的读写分离中间件,所以我们还是去调研了一些 Proxy 模式的数据库中间件,并在线上采用了。(3)
API Gateway
自研 API Gateway 是迟早的事情,因为 API Gateway 和自身业务关系紧密。(4)
优雅启动和优雅关闭
Java 程序启动太慢,Golang 程序启动太快… 如何做到优雅启动和优雅关闭?(5)
HorizontalPodAutoscaler 支持自定义 Metrics
主要靠开源项目 k8s-prometheus-adapte 解决,整体难度不大。
但后面可以讲讲为什么需要让HorizontalPodAutoscaler 支持自定义 Metrics。(10)
AWS 账号与 Kubernetes 账号身份认证打通
同样是靠开源项目 aws-iam-authenticator。但是它只能解决认证问题,不能解决授权问题。我们的解决方案是通过脚本把 AWS User, Group 和 Kubernetes RBAC User, Group 做映射,来解决 Kubernetes 内部的权限管理问题。因为我们团队规模还不大,暂时没有产品化,只是一些简单的脚本。
I18N
我们是一个面向全球的 App,所以所有也许都要做翻译工作。之前单一程序通过一些脚本就可以做到翻译文件的管理,但现在业务拆开后,不可能每个项目中都把这部分代码重新实现一遍。做成中间件不现实,业务自己调对应的服务也不现实,如何配合 API Gateway 来解决这个问题呢?(6)
CI / CD
CI / CD 再次出现,原因很明显,第一版的 CI / CD 不好用,后续我们对它进行了改造。(7)
分布式上下文
一般 RPC 服务都会自动传播上下文,这样可以在调用链上游下游之间共享一些数据。但 Service Mesh 的重要一点是跨语言,RPC 协议也只是普通的 HTTP 或 gRPC,它们并没有相关协议。所以这块只能我们自己研发了。(8)
最后的单体程序改造
当最老的单体程序业务能拆的都拆了以后,它依然是那么庞大。随着公司发展,总有那么一堆代码,复杂,看不懂,但是又不能去掉它们。
花大精力去把这部分代码重构不现实,在业务变动不大的情况下,这部分代码完全可以继续运作。
但现在这个单体程序是我们所有流量的入口,很多迁移成独立服务的流量还是要经过它,它要处理身份认证等功能。
之前提到我们已经有自研的 API Gateway 了,那是不是可以把身份认证这样的功能迁移到 API Gateway 中,把已经改造完的项目直接通过 API Gateway 访问?把最老的单体程序中所有的通用功能迁移出来,只留下业务代码。最后再把它整体迁移到 Kubernetes 中,把它当成一个老业务的大杂烩服务。
这个想法其实由来已久,但一直没动工的原因就是 API Gateway 还没支持好所有的通用功能;另外 CI / CD 一开始也不成熟,这个项目很大,没有金丝雀发布,没有回滚功能的话不敢迁移。
最后,就在 2020 年初,把这两个障碍扫除后,我们也在近期完成了单体程序整体的迁移。
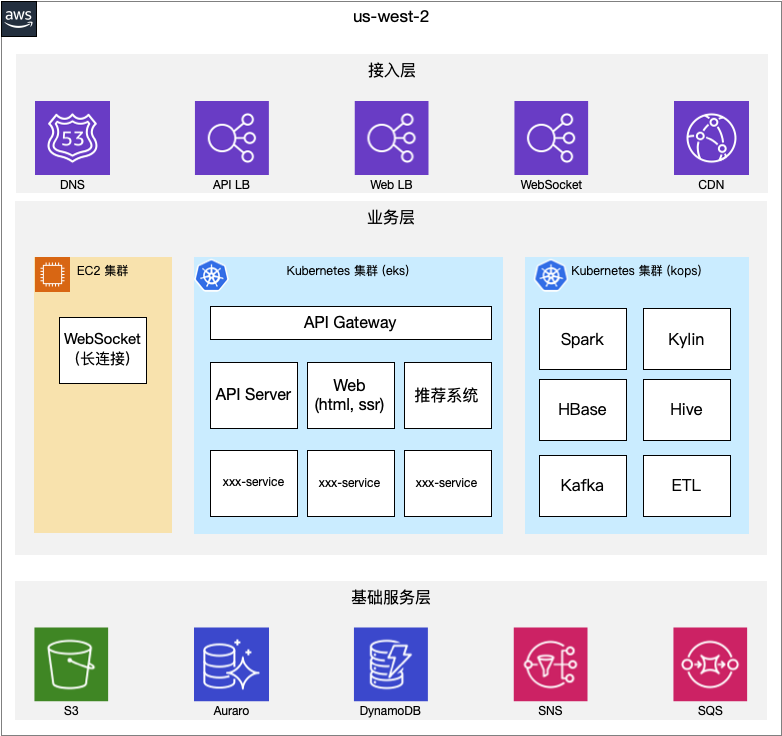
和上面的图对比一下,可以看到如下一些变化:
以前直接在 EC2 里跑的单体程序没有了,被改造成了一个 Kubernetes 里的服务。很多业务也都被拆成了独立的服务。
Kubernetes Ingress 从 Istio Ingress 换成了自研的 API Gateway。以前单体程序里的通用逻辑都在这里重新实现了一遍。
最后,存储也变得多样性了,业务变大以后 MySQL 不能满足所有需求了。
至此,我们的 Service Mesh 转型之路算是告一段落了!
更多内容
- Service Mesh 实践(一):从 kops 到 EKS
- Service Mesh 实践(二):Istio Mixer 模块的性能问题与替代方案
- Service Mesh 实践(三):数据库中间件
- Service Mesh 实践(四):从开源 Ingress 到自研 API Gateway
- Service Mesh 实践(五):优雅启动和优雅关闭
- Service Mesh 实践(六):I18N Language
- Service Mesh 实践(七):CI / CD 的变迁
- Service Mesh 实践(八):分布式上下文
- Service Mesh 实践(九):为什么 Golang 更适合 Service Mesh
- Service Mesh 实践(十):HorizontalPodAutoscaler 支持自定义 Metrics
本作品由 Dozer 创作,采用 知识共享署名-非商业性使用 4.0 国际许可协议 进行许可。