传统做法
以前的微服务架构中优雅启动和优雅关闭其实不难,这些东西本身就是自己实现的。
启动后先打点流量预热一下,然后把实例注册一下就行了;要关闭的时候就先取消注册,等待一段时间尽量让所有请求结束后再关闭。
另外,传统微服务架构下的实例启动关闭的频率也远低于 Service Mesh,做了 Service Mesh 这个问题也会更突出一点。
那具体遇到了哪些问题又怎么解决呢?
Golang + Istio 启动失败
这个问题是我们第一个遇到的,现象就是每次发布,新的Pod总是会出错一次,然后 Kubernetes 把它重启后再来一次就好了。
而且只有 Golang 程序有这个问题,Java 程序不会有。
重现步骤不难,先在集群内装好 Istio 再装一个最简单的 Nginx Server。
然后再写个简单的 Golang 程序,启动的时候立刻访问 Nginx 就可以了。
package main
import (
"fmt"
"net/http"
)
func healthCheck(w http.ResponseWriter, req *http.Request) {
fmt.Fprintf(w, "ok\n")
}
func main() {
_, err := http.Get("http://nginx/")
if err != nil {
fmt.Println(err.Error())
panic(err)
}
fmt.Println("Start Simple Http Server")
http.HandleFunc("/health-check", healthCheck)
http.ListenAndServe(":8080", nil)
}
然而你会发现,Golang 写的程序总是大概率在第一次启动的时候失败,Kubernetes 把它重启一次后才会正常。
NAME READY STATUS RESTARTS AGE
app-tester-7b999ff58c-4l7zb 2/2 Running 1 81s
查看Pod状态后发现是程序挂掉了,这时候日志还不容易看,因为容器已经重启了,直接看的话看到的是最新的日志。
kubectl describe pods app-tester-7b999ff58c-4l7zb
Containers:
app-tester:
Container ID: docker://2ef6f6bb8af84aca41f8d67ed30a348f528a6066260e8e2373f530e7d71a4c0d
Image: golang
Image ID: docker-pullable://golang@sha256:72218b6a9e51cbbd91980fb8c770b6a577e2165defcbb838108df96f58898d25
Port: 8080/TCP
Host Port: 0/TCP
Command:
./run
State: Terminated
Reason: Error
Exit Code: 1
Started: Thu, 27 Feb 2020 18:56:48 +0800
Finished: Thu, 27 Feb 2020 18:56:49 +0800
Ready: False
Restart Count: 0
如果你已经在集群内装了 Fluent Bit 等搜集日志的服务,那么可以很方便地看到重启前的日志了,如果没有,那么还需要登陆宿主机去找日志。
最后我们发现,是启动一瞬间的网络有问题,所以导致无法访问。
因为只有配合 Istio 才有问题,搜索后找到了对应的 Issue:https://github.com/istio/istio/issues/11130
原来,根本原因是 Envoy 还未启动完成的时候我们的业务就进行了网络请求导致的。因为 Istio 利用 Init Container 通过 iptables 早就把所有出口流量指向了 Envoy,如果 Envoy 还未启动完成,业务代码自然是无法进行网络请求的。
总结起来就是一句话,Golang 启动太快了!那 Java 为什么没问题了?因为 Java 启动太慢了,至少几十秒,自然就不会出现这个现象了。
目前我们的解决办法也很简单粗暴,所有 Golang 程序启动前 sleep 3 秒就解决了。另外也可以修改Deployment,加一个lifecycle.preStart,sleep几秒就行了。
Istio 优雅关闭
另一个问题更难解决一点,是主要是程序关闭的时候遇到地问题。
第一种现象是如果 A 访问 B,B再访问 C,此时一个请求正在等 C 处理,A 和 B 都在等待。如果关闭了 B,A 的这次请求就失败了。
理论上如果 B 程序处理地好,等待所有请求都结束后再终止程序,不应该有问题的。
可惜注入了 Envoy 后,Envoy 在这块处理地并不好。Envoy 在收到终止信号的时候立刻退出了。
https://github.com/istio/istio/issues/7136
相关地讨论很多,Envoy 和 Istio 后来已经解决了这个问题,这个问题比较好解决,一个设计良好地程序就应该支持优雅关闭。
但还有一个类似的问题就比较尴尬了。
如果 A 访问 B,B 再访问 C,此时如果一个请求正在进行中,B 正在处理自己的东西,还未请求 C。
这时候把 B 终止,B 的代码还在继续跑,当它想要请求 C 的时候,网络却不通了。
因为收到终止信号的时候 B 注入的 Envoy 没有活跃链接了,它也不会知道 B 还会不会再请求,所以它就退出了。
我们一开始用了一种简单粗暴的解决办法,修改了 Istio 代码,强制让 Envoy 在退出前 sleep 几秒,这种现象就会大大改善了。
最新新发布的 Istio 1.4 中已经支持通过参数修改 Envoy 的 lifecycle 了。
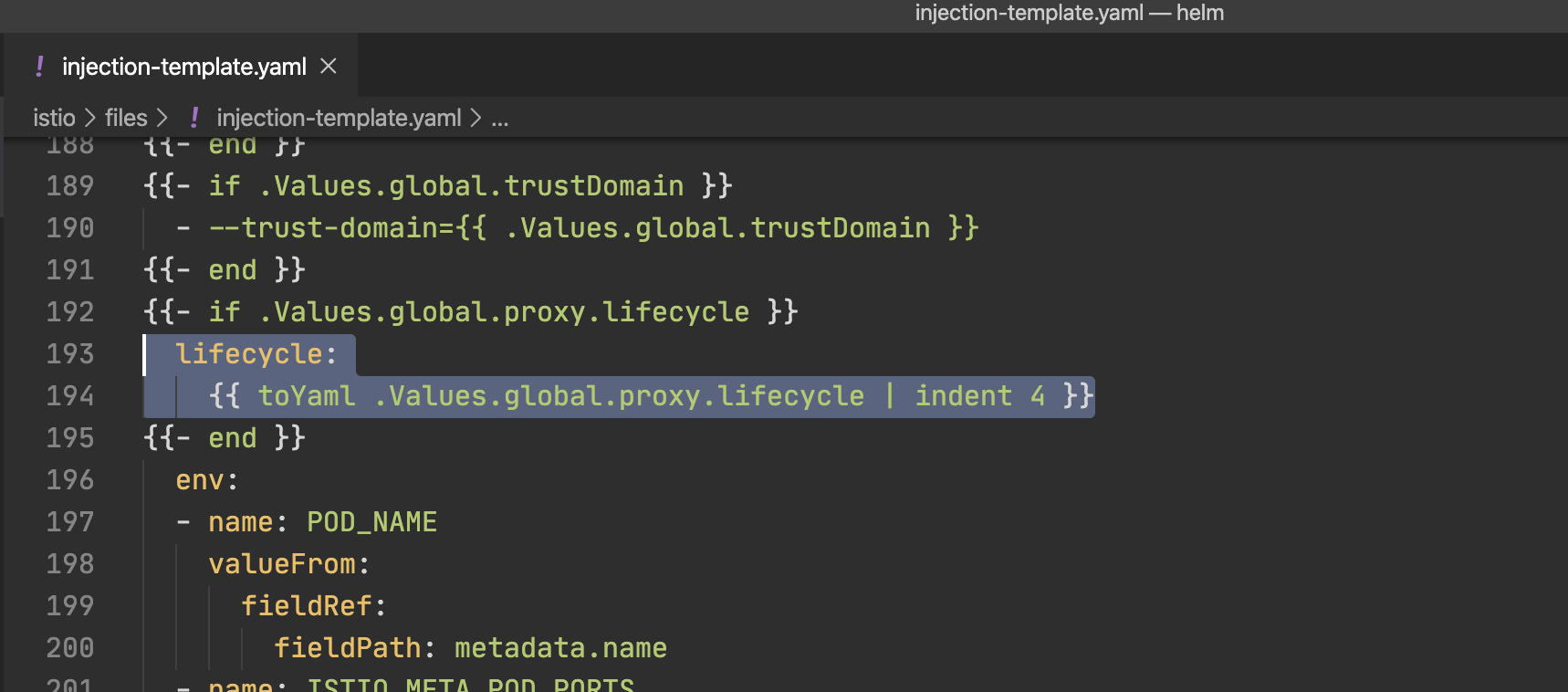
修改方法很简单,在 Istio 配置中加入这部分就行了:
global:
proxy:
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 15"]
但是文档还没更新,应该是还没来得及。其实我本来在写博客的时候也不知道这个变了,我只是想说一下应该改哪,翻阅源码的时候才看到它们已经支持了。
Kubernetes 对 Sidecar 的支持
真的要解决上面两个问题还是需要 Kubernetes 官方的支持了,因为同一个Pod中多个容器一般都是有一些依赖关系的,没有启动顺序这个功能的话会出很多问题。值得高兴的是,Kubernetes 准备在 1.18 中支持这种场景了。
https://banzaicloud.com/blog/k8s-sidecars/
1.18 中你可以把一个容器标记成sidecar,它会保证一定在你的程序启动前完成启动,也会保证在你的容器关闭后再关闭自己。

有了这个功能后,就能完美解决上面几个问题了。
Java 程序启动时负载过高延迟过大
Golang 的问题是启动太快了,而 Java 的问题就是启动太慢了…
Kubernetes 资源配置与自动扩容缩容
Kubernetes 的最佳实践中,要为所有Pod配置容器的资源请求和限制,细节可以看官方文档:https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
简单概括一下就是你要为你的容器配置四个参数:
resources.limits.cpu: 容器最多可以用多少 CPUresources.limits.memory: 容器最多可以用多少内存resources.requests.cpu: 为容器保留多少 CPUresources.requests.memory: 为容器保留多少内存
其中resources.limits下的两个参数底层就是用 cgroup 来做限制的,容器的 CPU 不可能超过这个值,内存超过了会 OOM。
而resources.requests下的两个参数是 Kubernetes 在机器上分配容器的时候用的。如果机器是 4 核,那么最多只能跑 4 个resources.requests.cpu=1的容器。
那resources.limits大于resources.requests会发生什么?这个其实就相当于超售了,因为大部分业务声明给自己保留 1 核 CPU 的时候,它大部分时间不能跑满。
CPU 超售问题不大,最多就是大家都慢一点而已,这只是应对突发情况用的。但是内存超售就不容易出事了,很容易导致 OOM。所以一般内存不会超售。
然后为了充分利用资源,一般都是配置HorizontalPodAutoscaler来实现自动扩容缩容,Kubernetes 可以根据你声明的资源数和实际使用的资源数做比较,如果用的很少就会缩容,如果用的多了就会扩容。
在低峰期我们的Pod就会自动缩容,把资源让出来给数据平台,这样可以节约不少钱。
但是到了高峰期,Pod开始扩容的时候 P90 总会飙得非常高。一般一个平均延迟 10ms 的服务在扩容的时候 P90 会达到 100ms 以上,并发大的服务最慢的时候甚至会到秒级。
当一个业务要更新代码的时候,也同样有类似的问题,总会导致上游调用方有少量报错。
为什么在 Kubernetes 里会有问题
Service Mesh 很多服务都是轻量级的,一般一个简单的 Java 服务资源配置大致是这样的:
resources:
requests:
cpu: 1
memory: 512Mi
limits:
cpu: 1.5
memory: 512Mi
这个在运行的时候没问题,CPU 额外超售了 50%,也不会太影响同一台机器上的别的业务。但在刚启动的时候编译过程中,需要大量 CPU 就显得力不从心了。requests.limits.cpu配置得太大会影响别的业务,配置得太小又会导致启动过程中 CPU 不够用无法快速响应请求。
而微服务架构下的服务一般不会拆那么小,也不可能跑在那么小的虚拟机下,所以这个现象不会非常明显。
另外 Kubernetes 内置Service,或是用了 Istio 以后的 Envoy,它们的负载均衡策略都是随机分配。所以如果一共有 3 个实例,当新启动一个后变成了 4 个,新的实例会一瞬间分配到 25% 的流量。
而微服务下的服务治理框架可以灵活地给新启动的业务分配流量缓解这个现象。
尝试分层编译优化
先试试从源头解决这个问题,看过 JVM 原理的一定能猜到这是 Java 即时编译导致的。新版本的 Java 已经废弃了老的-client和-server两个参数,而是利用分层编译把c1和c2两个编译器配合使用了。具体细节可以看这篇文章:JVM进阶 – 浅谈即时编译
基于 Java 1.8+,根据原理,我有几个方案:
- 跳过
c1,代码运行后直接用c2,类似以前的-server模式,对应参数:-XX:-TieredCompilation - 到
c1就停止,不会进行c2,类似以前的-client模式,对应参数:-XX:TieredStopAtLevel=1
我写了个简单的 Java Server,暴露一个 API,每次请求会访问一次数据库。代码里用到了 Spring MVC,Mybatis,所以这个看似简单的程序背后有大量的 class 需要被编译。
然后限制 CPU 使用最多 0.5 核。再用压测工具每间 10 秒压测一轮记录下相关参数。另外我也控制了 QPS,保证在预热完成后实际 CPU 占用大约在 0.3 核左右。
测试脚本很简单:
for n ({1..50}); do fortio load -quiet -qps 1000 -c 100 -t 10s http://app-tester:8080/ ; done
下面是测试结果:
# openjdk8 默认参数
java -jar app-tester.jar
| Time | P50 | P75 | P90 | P99 | P99.9 |
|---|---|---|---|---|---|
| 0s | 197.4 | 465.625 | 826.97 | 1886.29 | 2544.86 |
| 10s | 182.765 | 238.632 | 446.176 | 995.955 | 1812.9 |
| 20s | 99.205 | 160.3 | 267.201 | 1503.85 | 2551.17 |
| 30s | 95.7119 | 106.129 | 183.418 | 503.273 | 758.72 |
| 40s | 54.4359 | 89.8943 | 99.8245 | 193.144 | 246.976 |
| 50s | 63.6049 | 94.1969 | 108.253 | 192.8 | 280.769 |
| 60s | 55.2794 | 80.7453 | 95.5563 | 238.682 | 414.314 |
| 70s | 70.991 | 97.7175 | 134.101 | 558.424 | 1571.53 |
| 80s | 53.8337 | 83.1865 | 96.9365 | 175.921 | 276.923 |
| 90s | 55.6827 | 83.9577 | 99.0229 | 285.921 | 616.3 |
| 100s | 68.2399 | 91.0623 | 99.4049 | 450.0 | 1210.88 |
| 110s | 9.45747 | 22.6015 | 38.6823 | 89.0323 | 134.074 |
| 120s | 6.56564 | 9.21653 | 11.3129 | 17.7818 | 51.0 |
| 130s | 6.38191 | 8.77066 | 11.1053 | 16.1176 | 20.0 |
| 140s | 6.35324 | 8.74876 | 10.9444 | 15.0841 | 19.9286 |
| 150s | 5.90095 | 8.38842 | 10.4839 | 101.412 | 230.556 |
| 160s | 6.2864 | 8.5492 | 10.8375 | 17.7391 | 23.3668 |
| 170s | 6.47078 | 8.4787 | 10.6983 | 13.8976 | 16.7143 |
| 180s | 6.18094 | 8.41088 | 10.6717 | 16.2474 | 19.1111 |
| 190s | 6.40341 | 8.61996 | 10.7623 | 14.9554 | 16.7245 |
| 200s | 5.82933 | 8.4235 | 11.1083 | 17.7143 | 20.0 |
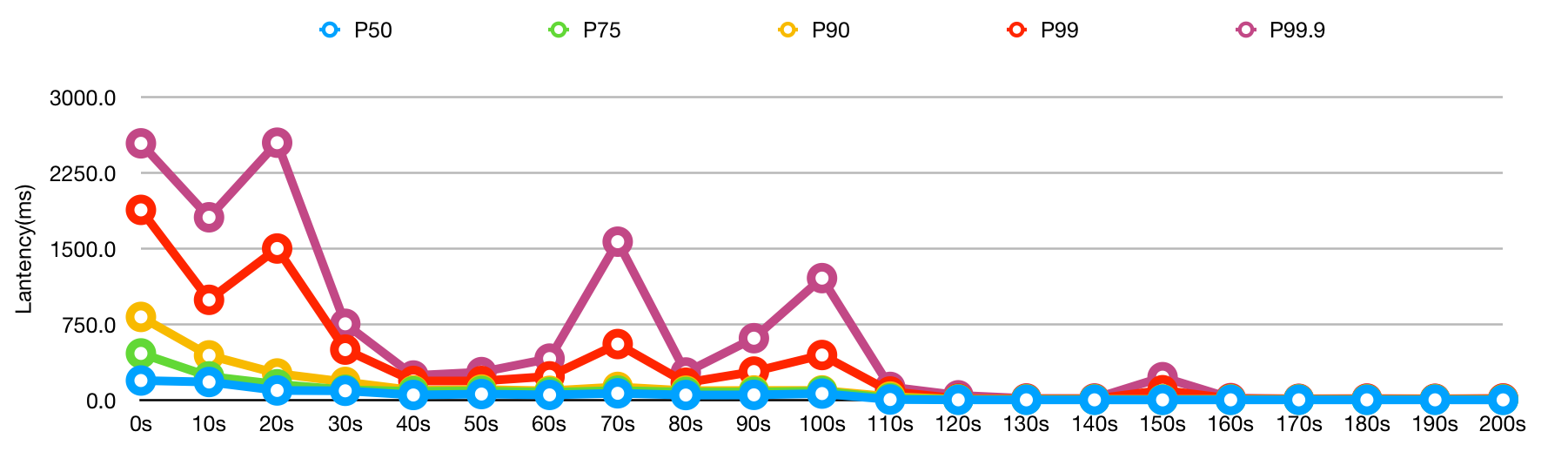
# openjdk8 直接用`c2`
java -XX:-TieredCompilation -jar app-tester.jar
| Time | P50 | P75 | P90 | P99 | P99.9 |
|---|---|---|---|---|---|
| 0s | 453.606 | 927.703 | 1655.03 | 2595.36 | 2863.36 |
| 10s | 371.242 | 544.75 | 800.857 | 1824.29 | 1989.57 |
| 20s | 277.313 | 396.031 | 629.881 | 1966.02 | 3400.33 |
| 30s | 217.866 | 318.429 | 462.0 | 1531.89 | 1965.35 |
| 40s | 193.299 | 260.764 | 393.448 | 1362.96 | 2096.43 |
| 50s | 113.403 | 195.336 | 301.646 | 1633.06 | 2397.96 |
| 60s | 99.6747 | 181.452 | 204.595 | 575.091 | 1527.4 |
| 70s | 98.4652 | 113.605 | 191.653 | 357.446 | 547.8 |
| 80s | 94.7329 | 103.684 | 181.441 | 225.585 | 372.63 |
| 90s | 39.6047 | 74.4492 | 93.5422 | 184.138 | 242.0 |
| 100s | 6.47826 | 8.70323 | 11.0 | 15.3176 | 17.641 |
| 110s | 6.47217 | 8.58247 | 10.2566 | 13.3855 | 20.8732 |
| 120s | 6.52315 | 8.65213 | 10.4059 | 14.466 | 17.2222 |
| 130s | 6.51371 | 8.95079 | 12.8831 | 491.522 | 1664.8 |
| 140s | 7.44685 | 10.3701 | 15.9692 | 95.098 | 116.327 |
| 150s | 5.81025 | 8.21096 | 10.4226 | 14.5373 | 186.301 |
| 160s | 5.97931 | 8.5613 | 11.2288 | 14.9781 | 17.7391 |
| 170s | 6.2186 | 8.42152 | 10.5688 | 16.7727 | 103.343 |
| 180s | 5.77665 | 8.2974 | 10.6585 | 14.3762 | 20.0 |
| 190s | 6.06703 | 8.39861 | 10.6397 | 15.7522 | 19.3684 |
| 200s | 6.72526 | 8.69675 | 10.2719 | 14.422 | 16.4739 |
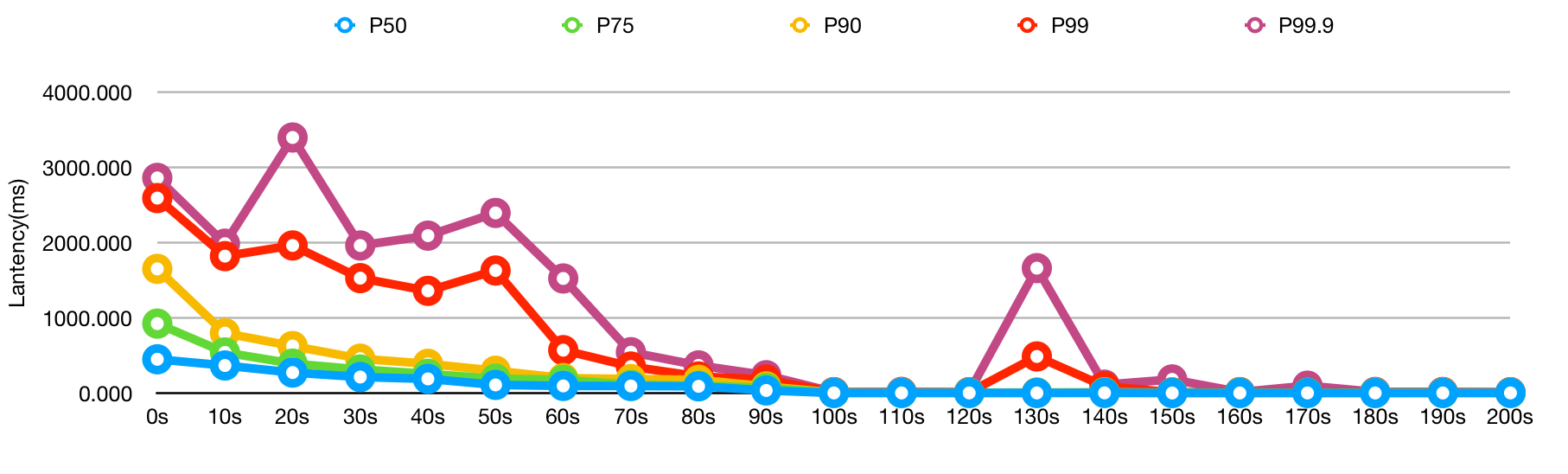
# openjdk8 只用`c1`
java -XX:TieredStopAtLevel=1 -jar app-tester.jar
| Time | P50 | P75 | P90 | P99 | P99.9 |
|---|---|---|---|---|---|
| 0s | 211.275 | 424.238 | 821.042 | 2786.87 | 3610.91 |
| 10s | 96.4706 | 108.599 | 191.273 | 494.333 | 949.333 |
| 20s | 10.2844 | 23.4359 | 63.6352 | 86.0784 | 98.6207 |
| 30s | 9.46099 | 15.5472 | 45.2062 | 76.5942 | 98.125 |
| 40s | 9.55367 | 13.2348 | 57.7083 | 85.3202 | 89.7537 |
| 50s | 9.1522 | 12.9049 | 23.0952 | 64.2593 | 82.2222 |
| 60s | 9.11557 | 12.6746 | 37.7211 | 65.5556 | 131.25 |
| 70s | 9.74239 | 13.1191 | 39.3182 | 87.6531 | 102.553 |
| 80s | 8.4283 | 11.9672 | 49.375 | 87.4699 | 99.0 |
| 90s | 10.1996 | 27.13 | 65.2153 | 78.6027 | 85.0 |
| 100s | 9.77195 | 17.5556 | 62.7608 | 77.1237 | 85.0 |
| 110s | 9.28459 | 12.2199 | 15.7638 | 74.0667 | 82.0 |
| 120s | 9.76496 | 14.0235 | 42.4895 | 58.5942 | 140.0 |
| 130s | 9.375 | 13.8936 | 55.1143 | 476.0 | 1273.44 |
| 140s | 10.2008 | 20.4795 | 41.8148 | 90.0 | 147.143 |
| 150s | 11.3643 | 43.3864 | 73.0446 | 170.252 | 284.783 |
| 160s | 11.8096 | 66.9327 | 93.0346 | 281.25 | 616.286 |
| 170s | 9.89216 | 16.4603 | 66.4623 | 107.273 | 262.5 |
| 180s | 10.0154 | 17.9604 | 49.9324 | 78.0159 | 131.429 |
| 190s | 9.32549 | 14.1396 | 35.3042 | 84.6721 | 97.8125 |
| 200s | 9.43291 | 12.44 | 33.3529 | 58.1505 | 147.661 |
经过对比,只用c1虽然前期稍微好一点,但是后期性能差太多了;直接用c2更加剧了前期的问题,虽然预热很快就结束了,但也无法接受。
尝试 Java 13 AppCDS
Java 从 10 开始提供 AppCDS,可以从这篇文章中了解到更多信息:Improve Launch Times On Java 13 With Application Class-Data Sharing
本质上是先把程序跑一遍,分析一下哪些 class 需要编译,然后提前编译一下缓存下来。
所以程序直接跑就不行了,需要提前预处理一下,这里的启动脚本需要改一下:
# openjdk13
WARM_UP=1 java -jar -XX:ArchiveClassesAtExit=app-cds.jsa app-tester.jar
java -jar -XX:SharedArchiveFile=app-cds.jsa app-tester.jar
这里对程序也进行了一点改动,会在启动完成后调用一下内部业务让 AppCDS 知道这个类需要被缓存,然后也要加一个环境变量,如果跑一下的目的是分析 class 缓存情况,那么启动完了就可以直接停掉了。
我这里内部是根据环境变量WARM_UP=1来判断的。也可以不实现这个,直接在启动脚本里固定时间把程序关闭。
结果如下:
| Time | P50 | P75 | P90 | P99 | P99.9 |
|---|---|---|---|---|---|
| 0s | 197.4 | 465.625 | 826.97 | 1886.29 | 2544.86 |
| 10s | 182.765 | 238.632 | 446.176 | 995.955 | 1812.9 |
| 20s | 99.205 | 160.3 | 267.201 | 1503.85 | 2551.17 |
| 30s | 95.7119 | 106.129 | 183.418 | 503.273 | 758.72 |
| 40s | 54.4359 | 89.8943 | 99.8245 | 193.144 | 246.976 |
| 50s | 63.6049 | 94.1969 | 108.253 | 192.8 | 280.769 |
| 60s | 55.2794 | 80.7453 | 95.5563 | 238.682 | 414.314 |
| 70s | 70.991 | 97.7175 | 134.101 | 558.424 | 1571.53 |
| 80s | 53.8337 | 83.1865 | 96.9365 | 175.921 | 276.923 |
| 90s | 55.6827 | 83.9577 | 99.0229 | 285.921 | 616.3 |
| 100s | 68.2399 | 91.0623 | 99.4049 | 450.0 | 1210.88 |
| 110s | 9.45747 | 22.6015 | 38.6823 | 89.0323 | 134.074 |
| 120s | 6.56564 | 9.21653 | 11.3129 | 17.7818 | 51.0 |
| 130s | 6.38191 | 8.77066 | 11.1053 | 16.1176 | 20.0 |
| 140s | 6.35324 | 8.74876 | 10.9444 | 15.0841 | 19.9286 |
| 150s | 5.90095 | 8.38842 | 10.4839 | 101.412 | 230.556 |
| 160s | 6.2864 | 8.5492 | 10.8375 | 17.7391 | 23.3668 |
| 170s | 6.47078 | 8.4787 | 10.6983 | 13.8976 | 16.7143 |
| 180s | 6.18094 | 8.41088 | 10.6717 | 16.2474 | 19.1111 |
| 190s | 6.40341 | 8.61996 | 10.7623 | 14.9554 | 16.7245 |
| 200s | 5.82933 | 8.4235 | 11.1083 | 17.7143 | 20.0 |
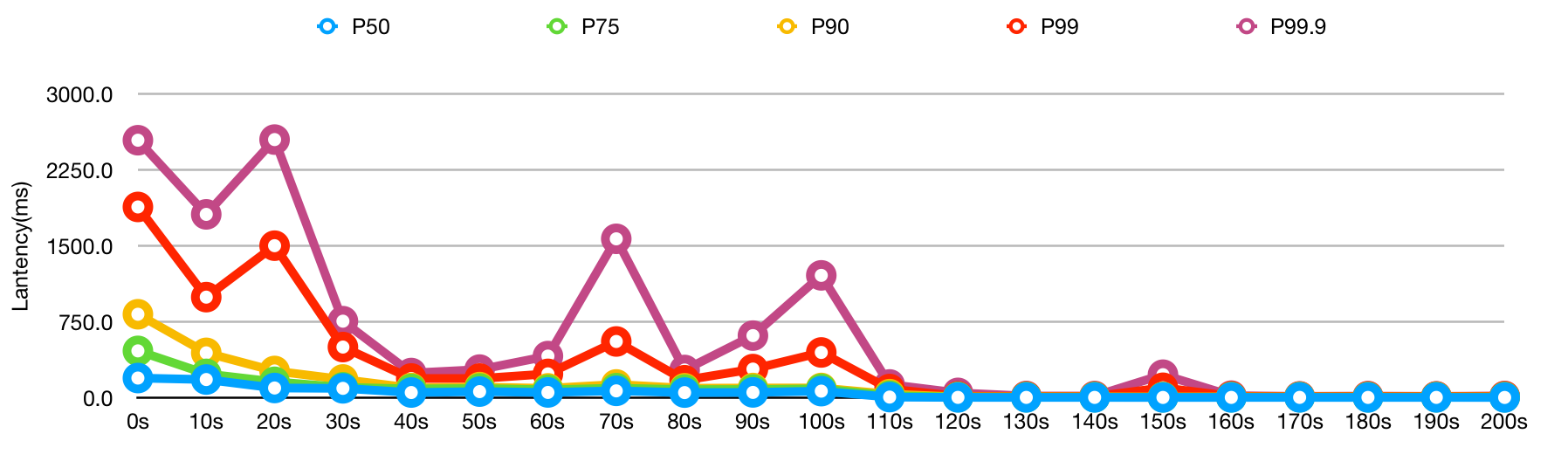
好像效果并不是非常明显,这也正常,因为我的预热代码是不可能覆盖所有真正要跑的代码的。
能否让程序在长时间运行的时候顺便把这些信息缓存下来,然后在下一次启动的时候直接用呢?因为这种模式下缓存下来的才是真正有用的。
尝试 OpenJ9
后来又发现 OpenJ9 在这块做得非常强大,细节可以看这两篇文章:
OpenJ9 配置起来非常简单,而且它可以做到所有 JVM 程序共享同一份缓存,缓存满了以后它能自动清理长时间不用的 class。
除此以外,它还可以大幅减少 JVM 内存占用。因为一个简单的 Java 程序跑起来后大部内存都是公用框架占用的。
在 Kubernetes 里想要用到这个的话,需要把这个共享文件挂在到宿主机上,否则放在容器内的话一启动就丢失了,也就没有意义了。
我这里会压测两次,第一次是预热,让它生成缓存。第二次是真正的压测,直接贴上第二次压测的结果:
# openjdk8-openj9
# 打印一下统计信息,确认缓存有效
java -Xshareclasses:cacheDir=/tmp/java/cache,printStats -Xscmx256M
java -jar -Xshareclasses:cacheDir=/tmp/java/cache -Xscmx256M -Xtune:virtualized app-tester.jar
打印出的缓存信息说明缓存的确有效:
Current statistics for cache "sharedcc_root":
Cache created with:
-Xnolinenumbers = false
BCI Enabled = true
Restrict Classpaths = false
Feature = cr
Cache contains only classes with line numbers
base address = 0x00007FCEE4059000
end address = 0x00007FCEF4000000
allocation pointer = 0x00007FCEE4ECE618
cache size = 268434848
softmx bytes = 268434848
free bytes = 214523260
ROMClass bytes = 15160856
AOT bytes = 14677324
Reserved space for AOT bytes = -1
Maximum space for AOT bytes = -1
JIT data bytes = 198972
Reserved space for JIT data bytes = -1
Maximum space for JIT data bytes = -1
Zip cache bytes = 921504
Startup hint bytes = 0
Data bytes = 363936
Metadata bytes = 1146436
Metadata % used = 2%
Class debug area size = 21442560
Class debug area used bytes = 2226388
Class debug area % used = 10%
# ROMClasses = 19693
# AOT Methods = 3852
# Classpaths = 31
# URLs = 0
# Tokens = 0
# Zip caches = 5
# Startup hints = 0
# Stale classes = 13522
% Stale classes = 68%
Cache is 20% full
Cache is accessible to current user = true
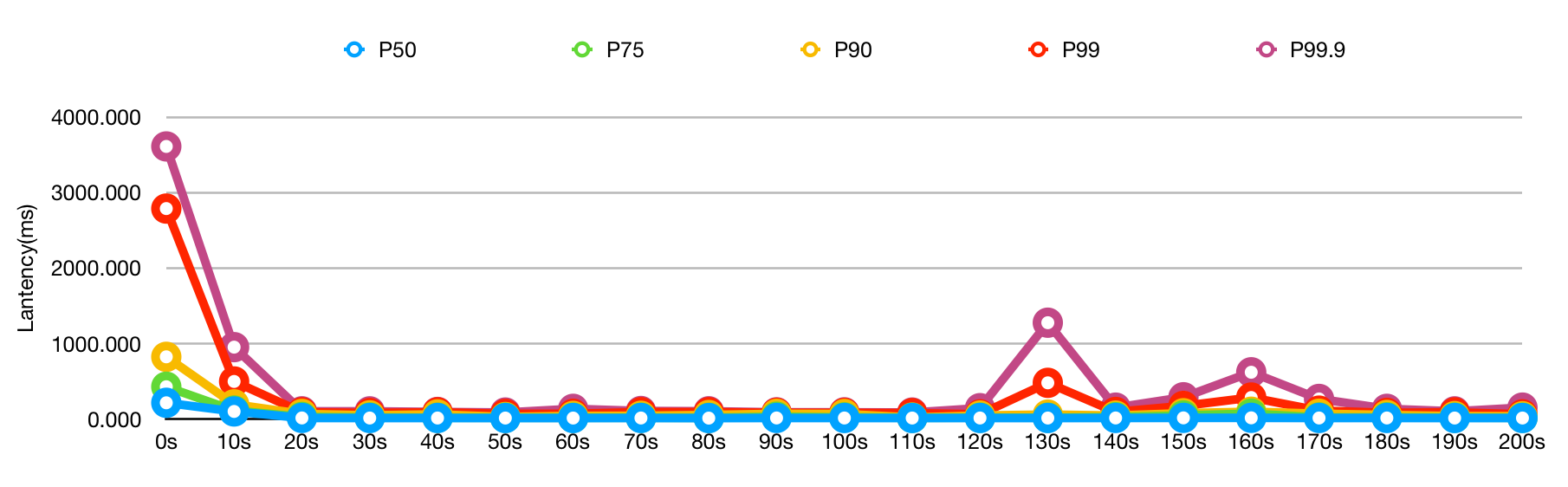
| Time | P50 | P75 | P90 | P99 | P99.9 |
|---|---|---|---|---|---|
| 0s | 102.454 | 188.202 | 278.445 | 2341.51 | 2727.5 |
| 10s | 67.1237 | 93.6605 | 111.917 | 288.161 | 500.546 |
| 20s | 47.2991 | 75.4605 | 89.9772 | 161.132 | 293.333 |
| 30s | 62.2794 | 85.4817 | 96.9474 | 229.545 | 416.667 |
| 40s | 49.8906 | 76.3703 | 91.7203 | 150.732 | 236.957 |
| 50s | 8.15622 | 11.1215 | 35.0 | 138.242 | 264.286 |
| 60s | 43.4973 | 70.217 | 85.4565 | 155.224 | 198.667 |
| 70s | 49.7949 | 75.8014 | 90.5059 | 152.414 | 228.125 |
| 80s | 9.25926 | 18.4314 | 87.8878 | 400.0 | 912.47 |
| 90s | 7.81955 | 10.5167 | 13.0704 | 61.2437 | 67.8283 |
| 100s | 7.43318 | 10.1478 | 12.7896 | 16.963 | 84.6154 |
| 110s | 7.2323 | 9.6565 | 12.1038 | 68.6 | 111.232 |
| 120s | 7.27096 | 9.58172 | 11.3835 | 58.5185 | 69.8592 |
| 130s | 7.87992 | 9.91841 | 11.604 | 14.7463 | 42.5 |
| 140s | 7.87443 | 10.1154 | 12.9932 | 69.172 | 87.0416 |
| 150s | 7.90534 | 10.4325 | 12.4497 | 24.0323 | 79.011 |
| 160s | 7.36498 | 9.81537 | 12.6328 | 65.4645 | 70.6221 |
| 170s | 7.34259 | 9.52754 | 11.1351 | 14.6988 | 41.7267 |
| 180s | 7.41449 | 10.0634 | 12.3634 | 46.358 | 51.5424 |
| 190s | 7.35043 | 9.78647 | 12.1596 | 19.8182 | 40.7143 |
| 200s | 7.80748 | 9.80591 | 11.1057 | 15.5394 | 17.7627 |
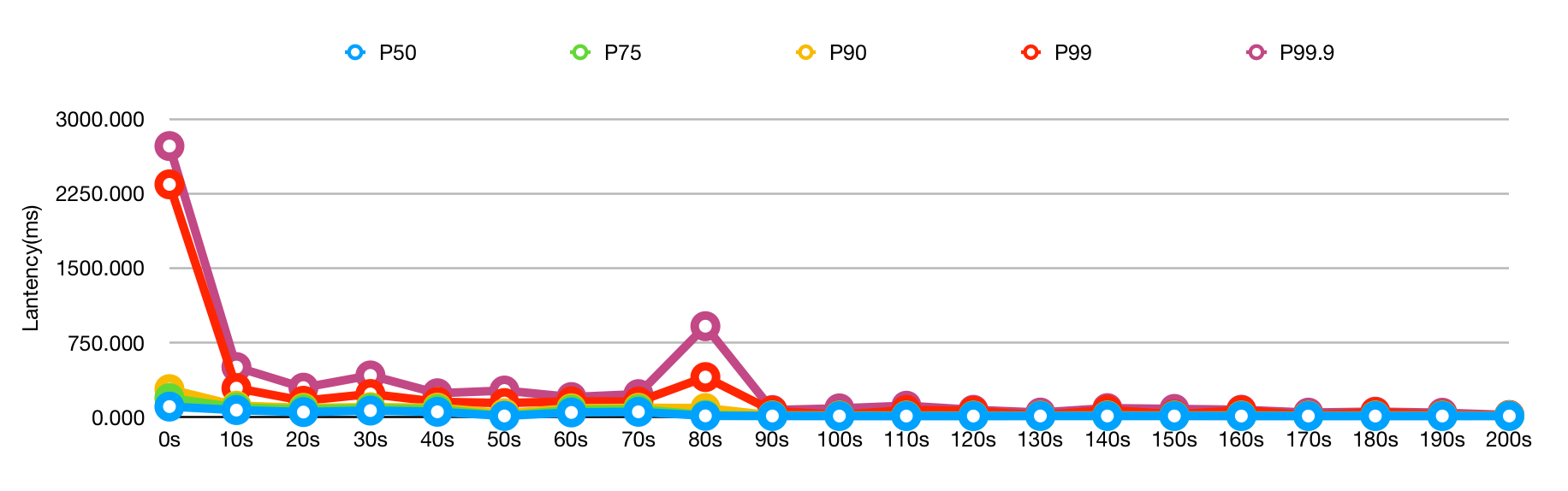
这个效果可以说是非常惊喜了,P99 和 P99.9 虽然前 10 秒高了一点,但是后面立刻降了下来,而 P90 简直是吊打别的方案。
当然,根据文档看这个是会影响吞吐量的,也就是说同样的 QPS 消耗的 CPU 会高一点,可以看到 P50 也稍微高了一点。
最后再把六个方案的 P90 放在一起看一下:
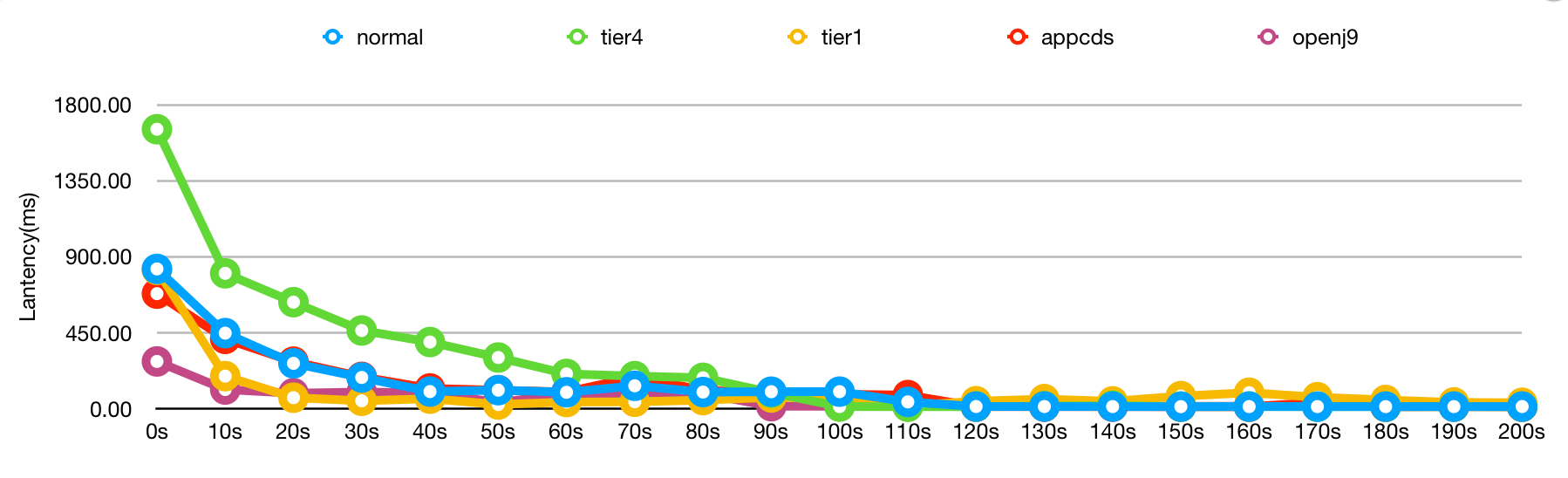
所以如何选择就要看你的取舍了,如果你的业务真的对冷启动很敏感,可以接受吞吐下降,那么 OpenJ9 是个很好的选择。
OpenJ9 除了启动预热速度快以外,内存消耗也非常小。一般一个 Spring Boot 的程序启动就要至少 200M 以上内存,最简单的程序都要分配个 512M。而用了 OpenJ9 后 class 都被做成了内存映射文件,所以工作内存占用会非常小,对于简单程序非常有优势。
除了从 JVM 角度优化,能不能从发布过程角度优化呢?
改变发布过程
既然传统微服务可以控制发布过程,那 Kubernetes 集群内从技术角度肯定也是可以实现的。
Kubernetes 本身没有这个能力,但是通过 Istio 其实是可以是实现的。
我们找到了这个开源项目:Flagger
它就是利用 Istio 的流量控制来精准地分配流量比例:
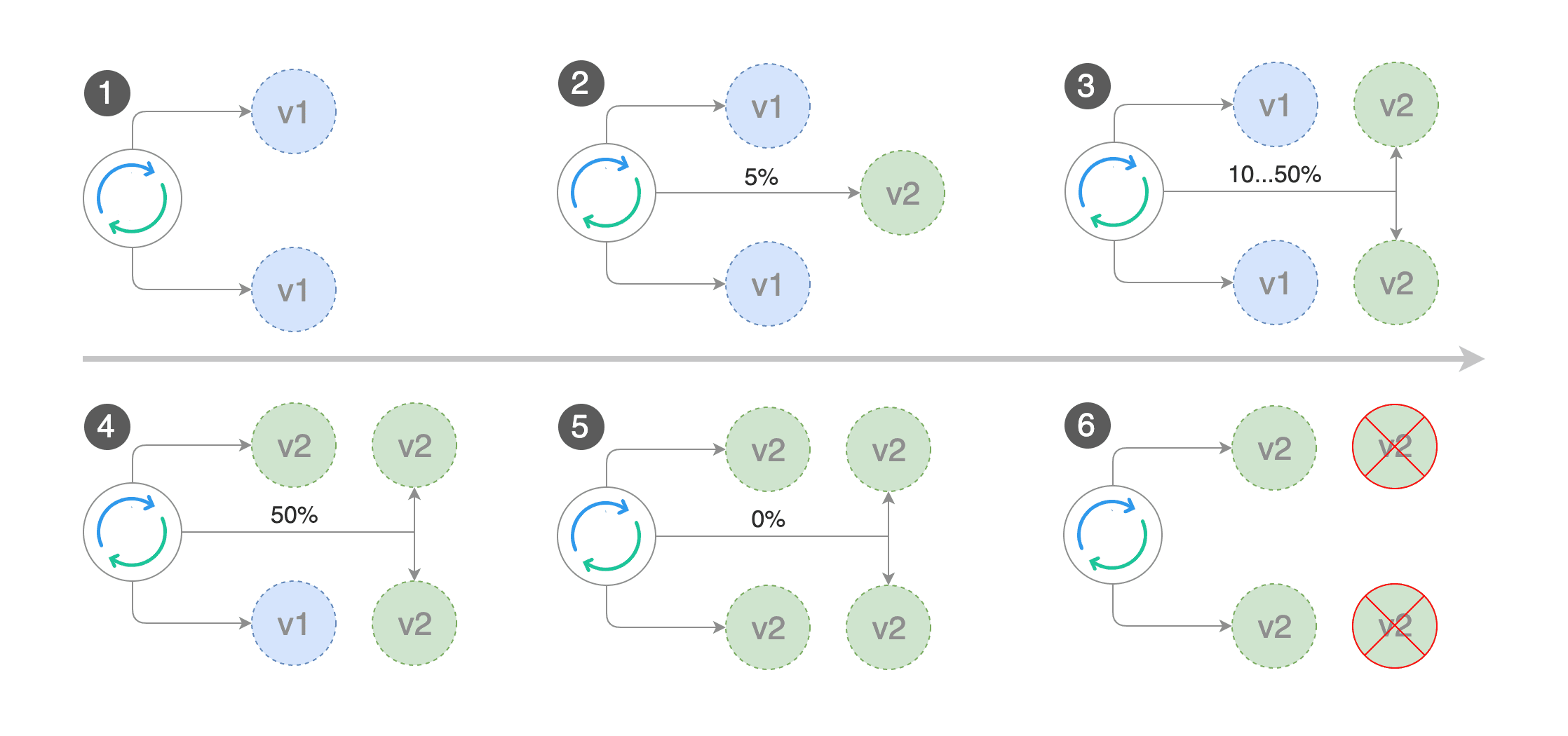
我们也在线上实测过,但实际效果上还有一点点偏差。因为它本质上不是为了解决我们这个问题而做的,它本身是为了做金丝雀发布或者蓝绿发布的。
但我们下一步可能会考虑利用这个开源项目改造出适应我们自己的方案。
总结
上面提的几个问题和很多方案,我们都在线上试验过,上面的测试结果也都是我严格控制环境测出来的。
针对三种情况,目前都有可以改善的不完美解决办法:
- Golang + Istio 启动失败:让业务容器比 Envoy 晚启动几秒
- Istio 优雅关闭:配置 Istio 安装参数,让 Envoy 比业务容器晚关闭几秒
- Java 程序启动时负载过高延迟过大:用 OpenJ9 或者自研发布控制工具
还好这个问题不算一个特别大的问题,只是作为一个工程师想尽量让启动和关闭的场景下可以 0 报错。
后面我们还会继续探索,想办法解决这些问题。
本作品由 Dozer 创作,采用 知识共享署名-非商业性使用 4.0 国际许可协议 进行许可。