Kubernetes Ingress
Ingress 的相关概念可以直接看 Kubernetes 的文档,讲的很清楚了:
简单的来说,它和传统服务器架构中的负载均衡器是类似的,本质上就是把集群内部的服务暴露给集群外。
internet
|
[ Ingress ]
--|-----|--
[ Services ]
这块技术方案非常多,要开发一个自己的 Kubernetes Ingress 也不难。看 Ingress Controllers 这篇文章,Ingress Controllers 的意思就是 Kubernetes Ingress 的具体实现。
两年前比较靠谱的方案主要是 Nginx Ingress 和 Istio Gateway,而现在技术方案已经非常多了。所有传统负载均衡厂商基本都为 Kubernetes 开发了 Ingress。
从严格的定义看,Istio Gateway 不能算是一个 Ingress Controller,因为它并不是根据 Kubernetes 里的Ingress资源来定义路由规则的。
Kubernetes Ingress 的理念是想做一层抽象,配置和实现解耦,所有的配置都是配置Ingress,而不需要关心具体的技术实现。
Istio Gateway 不用Ingress来配置,而是使用了自己的一套资源来配置,实际的功能上也比 Kubernetes Ingress 更丰富。因为技术实现脱离了 Kubernetes Ingress,所以我觉得严格的定义来看它不是一个 Ingress Controller。
Istio Gateway
既然我们用 Istio 做集群内的服务治理,那么用 Istio Gateway 也是合情合理的事情。因为 Istio Gateway 的相关配置和集群内整合了 Istio 的服务相关配置都是相同的,只需要配置一份就可以通用。而且功能上也比 Kubernetes Ingress 丰富的多。
我们一开始也不是没有用过,最早我们就是用的 Istio Gateway。
但是它有什么问题呢?
很早版本的 Istio 和 Helm 配合使用时有很多问题的,经常遇到升级版本出问题导致整个 Istio 只能卸载重来的情况。Istio 也一直在努力改善这个问题,例如现在版本把 CRDs 和 Helm Chart 分离;还有开发中的 Istio Operator 完全脱离 Helm。这些都是为了摆脱 Helm 带来的问题,毕竟部署 Istio 还是有点复杂的,模块太多。
另外从 Istio 的设计理念角度看,整个集群就算没有 Istio 也可以正常运作的,无非就是缺失一些辅助功能。遇到上述问题的时候,我们只能把 Istio 卸载重装,而在这个过程中,最大的问题就是 Istio Gateway 了。
用了 Istio Gateway 后,对 Istio 就有了强依赖,Istio Gateway 又是打包在 Istio 中的,无法独立管理。
最后考虑到未来我们一定是脱离这些搞自研的,所以决定摆脱 Istio Gateway 的限制,也不要让我们的集群对 Istio 产生太强的依赖。
Nginx Ingress
排除 Istio Gateway 后,开始尝试使用 Nginx Ingress,但是也遇到了一些问题。这里可以贴一些问题的排查思路和解决方案,结果不是最重要的,最重要的是解决问题的思路。
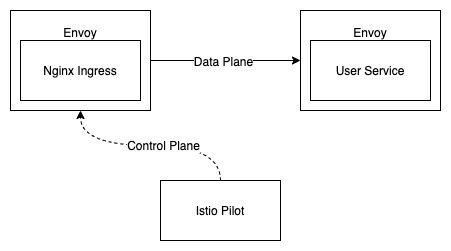
一开始我们搭建 Nginx Ingress 的时候是包着 Istio 的,因为如果不包着 Istio,Nginx Ingress 访问集群内部服务的时候就无法用到 Istio 相关功能了。
Envoy + Pilot 的配合其实是替代了 Kubernetes 内置的Service,做了一套自己的服务发现机制,因为这样才能实现更强大的流量控制功能。例如 A 服务访问 B 服务,B 服务中有一台主机会偶发性报 500,但它的 Kubernetes 健康检查却是正常的,没有完全挂掉。如果配置了DestinationRule的outlierDetection后,Envoy 会自动拆除目标机器。
和所有的流量控制一样,这套逻辑是在调用方来实现,而不是服务提供方实现的。按照这张图的例子,user-service的信息会由 Pilot 通过 xDS 协议推送给 Envoy,Envoy 就知道如果要访问user-service的时候要访问哪些 IP 了。启用 Istio 后user-service里面的Service并没有实际的作用了,只是用来给 Pilot 分析这个服务对应着哪些Pod而已。实际的流量也不会像 Kubernetes 里的Service一样通过iptables规则 NAT 转发到对应的Pod了。
我们这里来简单的搭建一个环境,方便后续演示。
本地跑 Kubernetes 技巧
我们先来改一个配置:
sudo ifconfig lo0 alias 100.64.0.0 255.255.255.0
这里有一个小技巧,国内在本机跑 Kubernetes 集群一直要面临翻墙问题。
虽然可以跑 SS,然后配置代理,但是 macOS 上的 Docker 都是基于虚拟机来实现的。
用虚拟机实现有什么问题呢,你的 SS HTTP Proxy 一般都是监听127.0.0.1:1087的。
如果你直接配置这个地址的话虚拟机内的127.0.0.1是虚拟机的本地回环地址,并不是你宿主机,所以无法直接访问。
解决办法也很简答,让 SS HTTP Proxy 监听0.0.0.0:1087,然后把你的局域网内网 IP 配置到 Docker 代理中就行了。
但你在公司,家庭来回切换的时候,内网 IP 是一直会变的,所以可以通过这个alias给你的网卡加一个别名,然后配置到 Docker 代理中就行了。一般配置一个不冲突的局域网 IP 就行了。
环境搭建
言归正传我们来搭建一下环境:
# Create Istio namespace
kubectl create namespace istio-system
# Install Istio
helm repo add istio.io https://storage.googleapis.com/istio-release/releases/1.4.5/charts/ # Install Istio helm repo
helm upgrade --install --force istio-init istio.io/istio-init --namespace istio-system # Install Istio CRDs
kubectl -n istio-system wait --for=condition=complete job --all # Waiting for Istio CRDs job done
helm upgrade istio -i istio.io/istio --namespace istio-system --set gateways.enabled="false" # Install Istio
kubectl label namespace default istio-injection=enabled # Enable Istio auto inject
# Install Nginx Ingress
helm upgrade -i nginx-ingress stable/nginx-ingress
创建服务
安装一个测试用的user-service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-service
spec:
selector:
matchLabels:
app: user-service
replicas: 1
template:
metadata:
labels:
app: user-service
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: user-service
labels:
app: user-service
spec:
ports:
- port: 80
protocol: TCP
selector:
app: user-service
配置 Ingress
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
name: user-service
spec:
rules:
- host: user-service.dozer.cc
http:
paths:
- backend:
serviceName: user-service
servicePort: 80
一览
目前集群内default命名空间下有这些东西:
NAME READY STATUS RESTARTS AGE
pod/nginx-ingress-controller-6f65cf7dcd-tjt9g 2/2 Running 0 16m
pod/nginx-ingress-default-backend-576b86996d-8b66l 2/2 Running 0 16m
pod/user-service-8dc746bfb-jvcn4 2/2 Running 0 5m13s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3h2m
service/nginx-ingress-controller LoadBalancer 10.97.233.209 localhost 80:32095/TCP,443:30051/TCP 20m
service/nginx-ingress-default-backend ClusterIP 10.104.45.225 <none> 80/TCP 20m
service/user-service ClusterIP 10.100.97.73 <none> 80/TCP 5m13s
访问 Nginx Ingress
因为这是本地的 Kubernetes 集群,service/nginx-ingress-controller 虽然类型是LoadBalancer,但实际上还是访问不到的。
所以只能用port-forward来访问 Nginx Ingress 了。
kubectl port-forward service/nginx-ingress-controller 8080:80 &
curl localhost:8080 -H Host:user-service.dozer.cc
检查结果
Nginx 是根据Host来把流量分发到对应的服务的,所以要在curl里传一下Host。然后看一下user-service的 Access Log,就可以看到访问日志了:
kubectl logs -l app=user-service -c nginx
127.0.0.1 - - [25/Feb/2020:11:56:51 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.64.1" "127.0.0.1"
Nginx Ingress 出口流量问题
环境搭建好了,访问也通了,本来以为一切很完美,但是当我们用上 Istio VirtualService 的时候就出问题了。
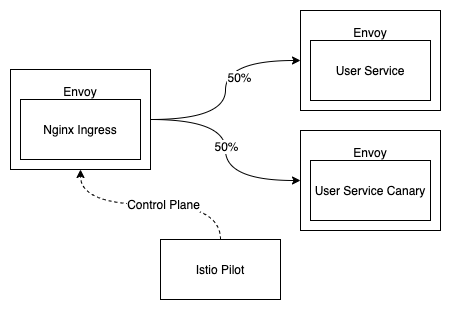
再创建一个服务
我们再创建一个服务user-service-canary做灰度发布:
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-service-canary
spec:
selector:
matchLabels:
app: user-service-canary
replicas: 1
template:
metadata:
labels:
app: user-service-canary
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: user-service-canary
labels:
app: user-service-canary
spec:
ports:
- port: 80
protocol: TCP
selector:
app: user-service-canary
配置VirtualService
然后配置一个VirtualService把 50% 的流量切到user-service-canary:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: user-service
spec:
hosts:
- user-service
http:
- route:
- destination:
host: user-service
weight: 50
- destination:
host: user-service-canary
weight: 50
VirtualService的本质就是转换成了 Envoy 的配置,告诉 Envoy 按照特定的规则分配流量,并不会产生什么新的东西。
无法命中user-service-canary
然而,再以curl访问的时候,却发现永远无法命中user-service-canary,难道是 Istio 的问题?
尝试直接启动一个Pod然后在内部 debug 一下。
kubectl run debug --generator=run-pod/v1 --rm --image=curlimages/curl:latest -it sh
结果发现一切正常,可以命中user-service-canary。
后来看了一下 Nginx Ingress Access Log,发现了一些奇怪的现象:
127.0.0.1 - - [25/Feb/2020:12:16:59 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.64.1" 84 0.001 [default-user-service-80] [] 10.1.0.37:80 612 0.001 200 56c050d5862b25d5f172b4ed202f407d
127.0.0.1 - - [25/Feb/2020:12:16:59 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.64.1" 84 0.002 [default-user-service-80] [] 10.1.0.37:80 612 0.002 200 3a8a4a2091b5abd02ca6c196bfbb8673
127.0.0.1 - - [25/Feb/2020:12:16:59 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.64.1" 84 0.002 [default-user-service-80] [] 10.1.0.37:80 612 0.002 200 92433895e58897905011817b55822d4d
这里10.1.0.37:80竟然是user-service Pod 的 IP,但是按照我的理解,Nginx 不应该访问user-service Service 的 IP 吗?如果没有 Istio,底层是 NAT 转发到对应的Pod的。
Access Log 里显示的应该是Pod IP。后来搜索后找到了答案,原来 Nginx Ingress 默认会和 Istio 类似,去找到对应Service的Pod IP,然后直接访问Pod IP。
这个默认行为其实和普通的 Nginx 类似,普通的 Nginx 在配置反向代理的时候,DNS 解析到下游 IP 后就会把这个 IP 缓存,后面并不会更新它。
修改 Nginx Ingress 默认行为
后来一番搜索后通过这个 Issue 找到了对应的解决办法:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/service-upstream: "true"
nginx.ingress.kubernetes.io/upstream-vhost: user-service.default.svc.cluster.local
name: user-service
spec:
rules:
- host: user-service.dozer.cc
http:
paths:
- backend:
serviceName: user-service
servicePort: 80
这两行新的配置的意思就是让 Nginx Ingress 用Service的 IP,另外作为一个反向代理一般都会把Host透传,所以这里也要强制把Host改掉,否则 Envoy 不认识这个域名。
这个问题就通过这种手段解决了。
另外 Envoy 究竟是根据什么来做路由的呢?一般反向代理都是根据域名的,那哪些域名会被 Envoy 路由到user-service呢?
Istio 已经提供了一些 debug 工具可以让我们看到 Envoy 最终的配置。这个对后续的各种 Istio 配置检查很有帮助,因为当有些 Istio 配置无法理解的时候,可以看看它在 Envoy 那边是什么样的。然后再去查看 Envoy 的文档,会清晰很多。
istioctl dashboard envoy {pod-name}
运行这行命令后会在浏览器打开一个窗口,可以看到很多 Envoy 的信息,其中 config_dump 就可以看到 Envoy 配置的细节:

Nginx Ingress 入口流量问题
另外一个问题也很棘手,我们看监控的时候总是发现 Nginx Ingress 运行的时候Pod 流量非常不均衡。很明显是启动早的流量多,启动晚的流量少。
这种现象在做负载均衡的时候很常见,一般是 HTTP Keep Alive 机制导致的。
我们的集群并不是直接暴露在公网的,公网流量是经过 AWS Load Balancer 进来的。暴露在公网的负载均衡器一定要足够稳定,否则一旦出现故障虽然可以通过 DNS 切换做故障转移,但是总是需要一点时间的。所以直接把集群内的机器暴露在公网是不合适的,集群内的机器稳定性远不如 AWS Load Balancer。另外从安全的角度,直接把集群暴露在公网也是非常危险的。
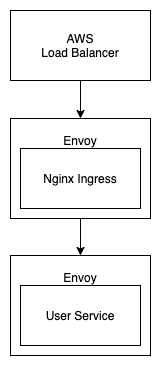
上图是我们集群南北流量的路径,这个问题很明显,肯定是 AWS Load Balancer 和 Nginx Ingress 之间保持着一个长连接并且长时间不关闭。
抓包验证问题
为了验证这个问题,想要抓包看看SYN包的数量是不是正常。
Kubernetes 里抓包不是一个简单的事情,想要真多某一个容器抓包的话还要登陆宿主机。这里有对应的教程:Kubernetes 问题定位技巧:容器内抓包
当然,现在已经不用这么麻烦了,已经有了一些更便捷的工具:https://github.com/eldadru/ksniff
抓包后,线上SYN包的确非常少,和 QPS 比起来少得多,完全不是一个正常的比例。
尝试从 AWS Load Balancer 这端解决问题
发现了问题解决起来也不难,AWS Load Balancer 和 Nginx Ingress 都是反向代理,一般反向代理都可以配置。
先是去 AWS Load Balancer 这边找,结果没有结果,提了 ticket 后确认 AWS Load Balancer 没有提供这个功能。AWS Load Balancer 可以保证流量是均衡的,但是不会主动断开连接。
AWS Load Balancer 虽然没有 Keep Alive 最大请求数这个功能,但是它会自动保持连接数在所有机器之间的平衡,看着也很合理。可是我们的连接并不均衡啊!
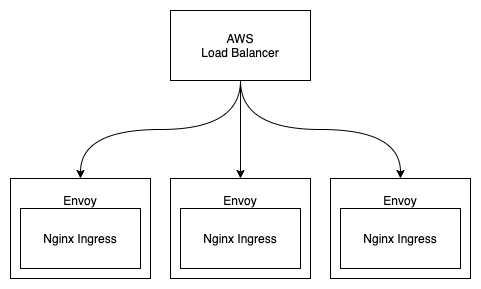
按照我当时的理解,如果有 3 个 Nginx Ingress,并且有 3 个连接,那么 AWS Load Balancer 会均衡分配连接。
为了验证 AWS 有没有在忽悠我们,还是决定自己验证一下。AWS 遇到问题第一位帮我们解决问题的客服一般不会深入看我们的案例,只会找到一些文档并贴给我们。
我们登上了宿主机并利用ss看了下来自于 AWS Load Balancer 的 TCP 连接数,但是竟然找不到来自 AWS Load Balancer 的连接!
嗯,有点懵了。
理解底层原理
按照经验,遇到这种情况一般都是自己对某一块的理解不够充分,我们这里用了 NodePort 来暴露的 Nginx Ingress 服务,按照 Kubernetes 的解释,就算只有一个 Nginx Ingress 在运行,只要配置了 NodePort 后,整个集群任何一台宿主机的特定端口都可以访问到这个 Nginx Ingress 服务。
https://kubernetes.io/docs/concepts/services-networking/service/#nodeport
当时对这块理解还不够深入,但仔细想想,这里是怎么做到的呢?常见的技术方案就是反向代理等技术。但如果是反向代理应该也能看到 TCP 连接。
再仔细阅读文档和相关资料后,终于搞清楚了这块的原理。原来这里的原理和 Kubernetes 里访问Service的原理差不多,都是底层配置了 iptables 实现了 NAT 转发。
那我们来看看 Kubernetes 生成的 iptables 规则具体是怎么样的,这里只保留 Nginx Ingress 相关的规则:
iptables -t nat -L
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- anywhere anywhere /* ingress/nginx-controller:http */ tcp dpt:30240
KUBE-SVC-RDGZDELSJT2I3HUE tcp -- anywhere anywhere /* ingress/nginx-controller:http */ tcp dpt:30240
Chain KUBE-SVC-RDGZDELSJT2I3HUE (2 references)
target prot opt source destination
KUBE-SEP-UUSTZY7K4CEISA6G all -- anywhere anywhere statistic mode random probability 0.50000000000
KUBE-SEP-DUN7RLIPNVSKRQPN all -- anywhere anywhere
Chain KUBE-SEP-UUSTZY7K4CEISA6G (1 references)
target prot opt source destination
KUBE-MARK-MASQ all -- ip-100-64-156-45.us-west-2.compute.internal anywhere
DNAT tcp -- anywhere anywhere tcp to:100.64.156.45:80
Chain KUBE-SEP-DUN7RLIPNVSKRQPN (1 references)
target prot opt source destination
KUBE-MARK-MASQ all -- ip-100-64-229-39.us-west-2.compute.internal anywhere
DNAT tcp -- anywhere anywhere tcp to:100.64.229.39:80
这里可以看到 NodePort 指向了 Nginx Ingress 的Service,然后Service的目标有 2 个,对应着两个Pod,并且是随机按概率访问的。
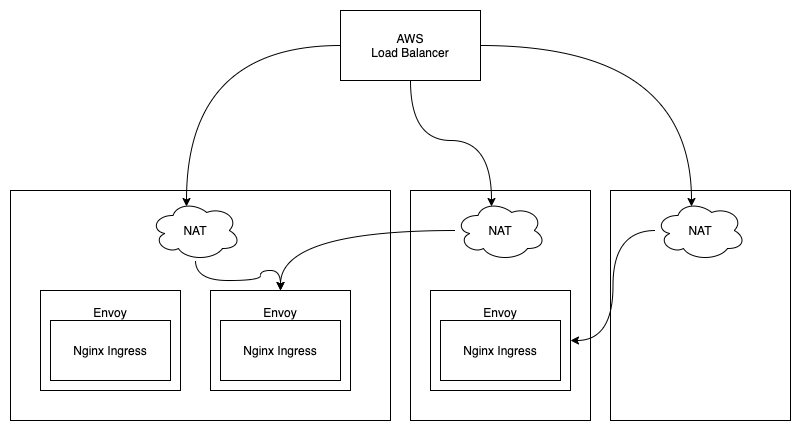
也就是说,就算 AWS Load Balancer 能严格控制连到各台宿主机的 TCP 连接数,但是最终进行 NAT 转发的时候是随机分配的,所以会出现上图这种情况。
这也解释了为什么运行时间越长的Pod分配到的连接数越多了。因为每个新链接都是来一次随机分配,所以运行时间越长被分配到的连接就会越多。
另外,想要看 NAT 转发的连接就需要用netstat-nat。最后终于确认,AWS 没有骗我们,从 AWS Load Balancer 的角度看,它的连接的确是均衡的。
尝试从 Nginx Ingress 这端解决问题
既然 AWS Load Balancer 不支持,那 Nginx Ingress 肯定支持这样的配置吧。
搜索一番后找到了对应的配置,Nginx Ingress 支持上下游分别控制,配置分别是:
keep-alive-requestsupstream-keepalive-requests
然而,事与愿违,CPU 还是不均衡。这次问题在哪?
先尝试进入 Nginx Ingress 抓包,明明是有断开连接的,接下来再准备看看 Nginx Ingress 里的 TCP 连接情况。
这时上面提到的Pod内抓包工具就不够用了,我还需要在Pod运行更多的命令。而容器化后的镜像大多是精简过的镜像,很多都直接把包管理干掉了,这也意味着你没办法直接进入Pod安装对应的工具。
最后找到一个更好用的工具:简化 Pod 故障诊断: kubectl-debug 介绍
它可以用你自己的镜像,加入到目标容器的各种 namespace 中,文件系统是你自己的,网络却是共享的,这样就可以很方便地排查网路问题了。
进入 Nginx Ingress “内部”后,看看 TCP 连接:
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 127.0.0.1:http 127.0.0.1:43094
这里就很奇怪了,为什么远端的 IP 是本地地址呢?之前同样是对 Istio 理解不深刻,并不知道入口流量也会被 Istio 劫持,后来查阅了相关文章后终于搞懂了技术细节:
原来这里 Nginx Ingress 只是断开了和 Envoy 之间的连接,而 Envoy 和 AWS Load Balancer 之间却没有断开。
终于,一切现象都解释得通了。
解决问题
所有的问题都搞清楚了,但是怎么解决呢?我们先来看看为什么 Istio 会拦截入口流量呢?流量控制只要拦截出口流量就行了。
其实,这个也不难解释,Istio 遥测这块就需要拦截入口流量,才能知道这个服务的相关信息。
而我们又禁用了 Mixer 模块,所以这个功能对我们来说是无用的,也就是说根本没必要让入口流量从 Envoy 走一遍,降低了性能还产生了问题。
要禁用这个功能也不难,只要在Pod的annotation上加上traffic.sidecar.istio.io/includeInboundPorts: "",就可以不拦截任何入口流量了。
配置后的确有效,最终解决了我们的问题。
另外 Istio 也有一个全局的配置,然而配置了却没用,查看 Istio 源码后发现它根本没用过这个配置。
自己解决也不难,就是改一下 yaml 文件而已,但是不理解他们的意图,还是先给官方提了个 Issue :global.proxy.includeInboundPorts is broken
自研 API Gateway
随着业务的发展,自研 API Gateway 的需求越来越大了,很多功能需要整合到 API Gateway 中,单纯的反向代理已经很难满足我们的需求了。
相关需求有:智能路由,限流熔断,分布式追踪,统一身份校验,CDN 静态资源防盗链签名,I18N,安全防护等。
正巧有一天看到了一篇 Caddy Plugin 开发的技术文章,发现基于 Caddy 的插件机制开发一个 API Gateway 在开发效率,运行性能等方面都很有优势。我们内部已经有不少业务用 Golang 来实现了,Golang 在 Service Mesh 这块也很有优势。
目前我们集群内所有流量都已经通过我们新开发的 API Gateway 来路由了,上述提到的需求我们也都已经实现。实现业务不难,难的是性能和稳定性。
性能
讲真,用了 Golang 的 pprof 后发现真的是非常好用。
经过压测和线上的分析后发现,主要的性能瓶颈就是 gzip, gunzip, json encode, json decode 等。可以发现这些都有一个共同的特点,大量的字符流和字节流的操作。
gzip 和 json 相关的都是很常用的技术,网上也有了很多的优化库可以提升这块的性能:
这两个库简单地替换以后,CPU 使用率就降低了 20% 以上。它们的优化方向主要是对象复用,还有一些算法的改进。
再往下看性能会发现大部分瓶颈都是在 GC 这块。这也是合情合理的,因为 API Gateway 作为一个反向代理,要把数据decode后还要做大量处理,然后再encode后返回给用户。这个过程和 gzip, json 处理类似,都是大量的字符流和字节流操作。
所以优化的思路和上面提到的两个库差不多,优化算法+对象复用。
因为这里的算法大多是特定业务的算法,不是像刷题算法那样是一个很单纯的问题,所以就不多介绍了,本质上就是一些文本处理的优化算法。而且这块收益也不是非常大。
这里主要看一下对象复用带来的收益。
上图是对象池取对象的每秒调用次数和新建对象的每秒调用次数对比,很明显用了对象池后,大部分对象都得到了复用,命中率非常高。
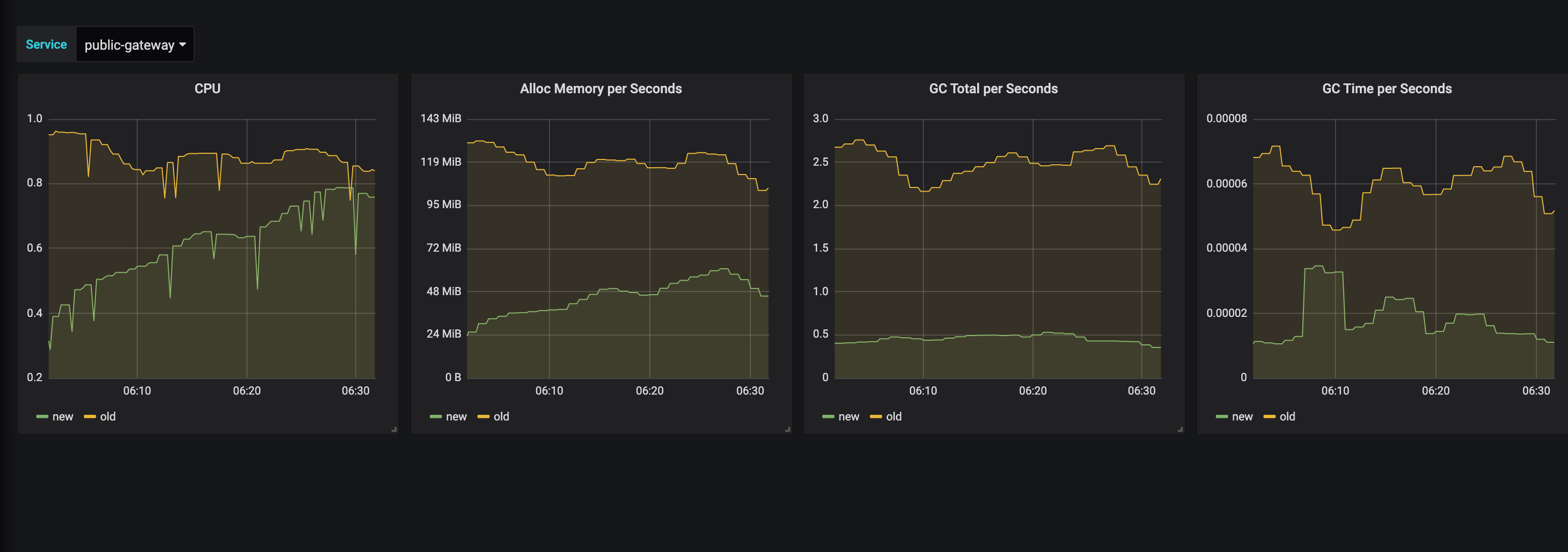
经过优化后,GC 次数和释放的数据也大大降低,CPU 使用率又有了大幅的降低。
稳定性
API Gateway 上线运行一段时间后有一些问题,下游业务常常会因为底层数据库或者是别的什么原因导致卡了一下,这一瞬间的并发请求数就会非常大,单个实例就会到几千甚至几万的并发请求。
大部分简单的 HTTP Server 都是多线程模式,每个请求由一个线程负责处理。当并发请求量一高,在 Java 中一个线程就要占用 1M 的栈,1000个并发请求就要占用 1G 的内存。一般 HTTP Server 都会在这种时候拒绝请求。
高级点的 HTTP Server 可以把接收请求和处理请求解耦。接收请求的部分用 IO 复用来实现,几十万的连接都不在话下。而处理请求的部分还是一个请求一个线程,这样对业务写代码会更友好。两个部分再通过两个队列来整合在一起。
而 Golang 就没这个烦恼了,Golang 协程的开销极小,编程的思路还是同步写法,但底层自动帮你处理了。于是它自信满满地把这些请求全部发送给了下游。
当下游返回数据的时候它就懵了,虽然没有了线程的开销,但几万个请求同时在 API Gateway 内部处理,返回的数据 10k, 100k 是很常见的,还要在内存里 gunzip 一下,虽然处理能力比 Java 强得多,但到了上千近万还是扛不住。
而 Golang 程序正常的时候占用内存极小,所以尽量节约资源,不会给它分配过多的内存,于是我们线上就经常会 OOM,一个实例 OOM,还会导致所有别的实例雪崩,线上还真的因此挂了很多次。
一开始我们也是简单地和传统 HTTP Server 限制一下最大并发请求数,可是这个数字太小就会出现很多被拒绝的请求,太大又会 OOM。
后来仔细想了想,这个问题对于 Golang 来说其实很好解决。一个请求过来后会检查当前并发请求数,如果数量太多就开始sleep自旋等待,最终要么等并发数降下去后继续执行,要么过了超时时间再抛错。
这个功能上线后,API Gateway 自身的稳定性大大提高,再也不会因为下游的不稳定而造成 OOM 了,在几秒内的卡顿不仅不会 OOM,也不会拒绝任何一个请求。
上面是我们的 API Gateway 长时间运行无重启的截图。
后续
API Gateway 该实现的功能大多数都实现了,后面随着服务越来越多,规则配置变更也会很多。目前配置是打包在代码中的,后面会考虑把配置做成动态配置再加上一个管理界面。
本作品由 Dozer 创作,采用 知识共享署名-非商业性使用 4.0 国际许可协议 进行许可。